На первом этапе система блокирует большую часть прокси трафика. Если прокси не заблокировано, то включается фильтрация на основе Js.
Cloudflare работает по следующей схеме. Браузеру выдается содержание не запрашиваемой страницы, а специально сгенерированной промежуточной. Промежуточная страница должна загрузиться полностью, включая картинки. И только после загрузки этого документа выполняются скрипты, которые разрешают дальнейшую загрузку — перенаправят на запрашиваемую страницу. Таким образом, без рендеринга промежуточной страницы извлечь содержание нужной страницы невозможно.
Итак, Js срабатывает только после того, как загрузится контент и картинки. Кроме того, коварный скрипт случайным образом может запустить антибот-тест. Если антибот-тест не пройден, дальнейшая выдача содержимого не производятся.
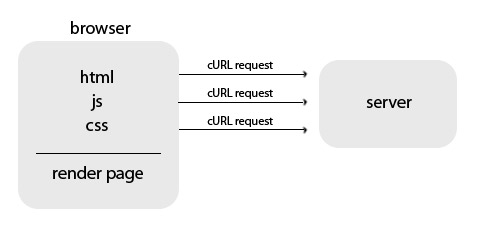
Если использовать CURL, то доставаться будет промежуточный контент, не содержащий необходимой информации.
Поэтому боты на базе CURL легко отсеиваются на этом этапе. А нам для получения содержимого страницы необходимо применить виртуальный браузер.
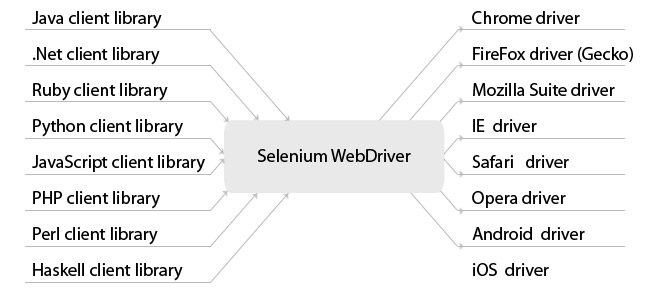
Важную роль играет выбор виртуального браузера.